
My Thoughts from Snowflake’s Data for Breakfast
Yesterday I walked into the Hilton Midtown in Manhattan for Snowflake’s “Data for Breakfast” event. I went in most interested in the “Make Your Data AI Ready” sessions. What I walked out with was a much broader picture of where the modern data platform is heading, and a few interesting nuggets of information.
Here’s what stuck with me.
The Ramp Story Changed How I Think About Data Democratization
The customer story came from Ian MacComber, Head of Data at Ramp. His talk had more substance than the usual vendor event case study.
First, credibility. Ramp is dealing with serious data volume. This wasn’t a startup with a few Postgres tables talking about their “data strategy.” Ian opened with a history of data engineering that genuinely resonated. He talked about the days before ROW_NUMBER() in SQL Server, when ordering result sets was painful. About having customers in one database and orders in another with no clean way to join them before big data and Hadoop came along. These felt like real inflection points in our industry, and hearing them framed as a progression gave useful context for where we are now.
But the part that hit hardest was their internal Slack bot: Ramp Research.
Ramp built a tool, exposed through Slack, where anyone in the company can ask natural language questions about their client data. The example that stuck: a salesperson heading to pitch a dental office can now ask the bot which dental practices are already Ramp customers. Name-dropping existing clients in a sales pitch is basic stuff, but traditionally that meant asking the data team, waiting for a query, and hoping someone got back to you before the meeting.
This reminded me of something from my own experience. Years ago, my co-founder Shitij constantly wanted to know what was happening with our users. How many presentations they were creating, how many papers they were adding into the product. And I was the bottleneck. Every question had to go through me because the data was locked up in the database and only I could query it. Ramp’s Slack bot is exactly the kind of thing that eliminates that bottleneck entirely.
The insight Ian shared that I keep coming back to: the questions people actually ask are surprisingly simple. Not complex analytical queries. Things like “which dental practices are in our client base?” It turns out these basic lookups are what drive everyday sales conversations. The value isn’t in the sophistication of the query. It’s in removing the friction between the question and the answer.
Ian also mentioned that Ramp is designed to break 30 times a day and be fixed fast. That’s a provocative framing. Most data teams treat any breakage as a failure. Ramp treats it as expected and optimizes for recovery speed instead. It raises a real question: what are the impacts of serving potentially bad data, and how do you encourage a feedback loop where everyone is reporting breaks instead of just the data team noticing?
AI Inside SQL Is Cool. And It Makes Me Nervous.
Snowflake demoed AI_CLASSIFY and other AI functions that run directly inside SQL queries. You can embed classification, extraction, and transformation logic right in your SELECT statement.
I’ll admit it: this is cool. It’s not a capability leap so much as nice syntactic sugar. You could do all of this with a Python pipeline before. But having it inline in your SQL, right next to your SELECT and WHERE clauses, changes the ergonomics in a way that matters for adoption.
But it also made me uncomfortable. Every one of these functions is Snowflake-specific. AI_CLASSIFY doesn’t exist in BigQuery. It doesn’t exist in DuckDB. It doesn’t exist anywhere else.
I just spent weeks building cross-database macros for my dbt project to handle the dialect differences between DuckDB and BigQuery. Each engine has its own way of doing things, and every proprietary function you adopt is another translation you’ll need if you ever move.
Snowflake embedding AI into SQL is a natural evolution. But it deepens the vendor lock-in problem. I would have preferred to see some movement toward a standards-based approach. Something that could eventually work across engines. Instead, each platform is racing to build its own proprietary AI primitives, and the gap between SQL dialects is only going to get wider.
Snowflake Is Starting to Look Like a Cloud
This was my biggest takeaway from the breakout sessions.
The “Modernize Your Data Estate” breakout covered Dynamic Tables and Semantic Views. Dynamic Tables are essentially computed tables that refresh on a set interval or, more interestingly, use their own intelligence to detect when upstream data has changed and refresh proactively. Semantic Views, generated by Cortex Code, are tables enriched with metadata and context so that AI agents can query the underlying data with full awareness of what the columns mean and how they relate.
Then came the product portfolio slide, and it hit me. Serverless tasks that look like serverless functions. Streamlit for app deployment. Native integrations for data ingestion from dozens of sources. Horizon Catalog for governance. Cortex for AI. Notebooks for analysis.
Snowflake is filling in the gaps so you don’t have to go to AWS, GCP, or Azure for the surrounding infrastructure. For a data-focused startup that wants to commit to one ecosystem and avoid the cognitive overhead of managing multiple cloud providers, this is a compelling value proposition.
The Orchestration Question
George Yates from Astronomer presented on taking AI from pilot to production, and he made a strong case for orchestration as the missing layer.
His argument: when you have many different data flows from different sources, things break at different cadences. Observability is often poor. Manual resolutions cause downstream data gaps. Infrastructure costs that haven’t been properly monitored create compounding problems. A dedicated orchestration layer gives you a single pane of glass across all of it.
I buy the premise. Deferrable operators that wait for data and save on infrastructure costs make a lot of practical sense.
But I kept circling back to one question. If platforms like Snowflake are already integrating with all these sources and giving you the means to pull data from everywhere, couldn’t they be the observability layer too? Why do I need another product? Maybe the answer is that Snowflake owns the warehouse and Astronomer owns the plumbing between everything else. But the boundary between those two keeps shifting.
DataOps as a Name for What I’ve Been Doing
The term “DataOps” kept showing up in slides throughout the event, and it was the first time I’d really sat with it. I’m very familiar with DevOps. I’ve been applying those practices to my data engineering work for years: version control for transformations, CI/CD for pipeline deployments, automated testing, environment parity. I just never had this specific label for it.
Sometimes naming a practice you already follow changes how you think about it. It makes it easier to communicate to clients and collaborators. “I apply DataOps principles” is more concrete than “I treat data pipelines like software.” Worth adopting.
What I’m Taking Away
The through-line of the event was clear: Snowflake wants to be the platform where all your data lives so that AI agents can consume it. Structured, semi-structured, freeform. Images, audio, anything. Unified, governed, and queryable.
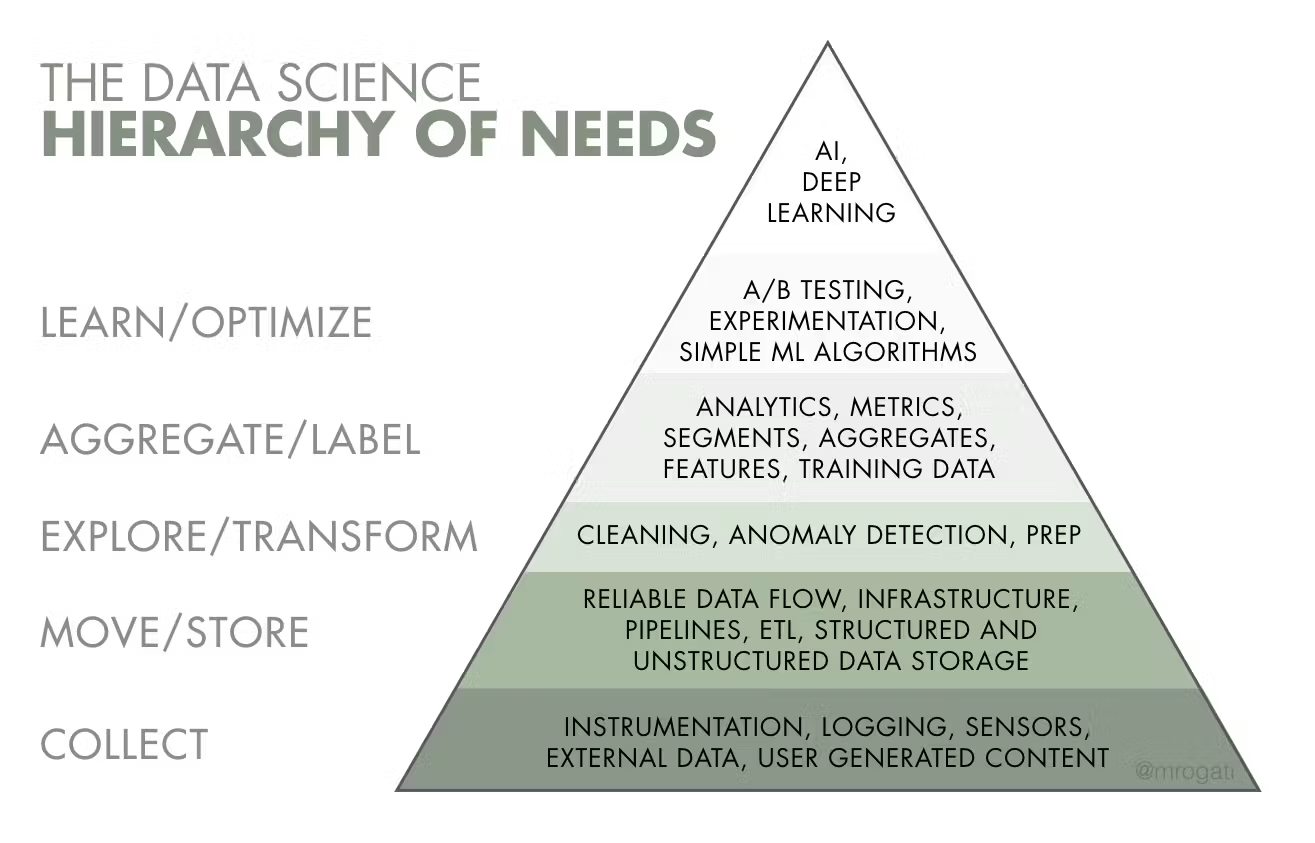
That’s a big promise. The pieces I saw yesterday are real. Dynamic Tables, Cortex AI functions in SQL, Semantic Views with rich metadata, Iceberg for open table sharing across organizations. The maturity model they presented for going from basic data warehousing to full AI-readiness was one of the best illustrations I saw all day (credit to Monica Rogati){:target=”_blank”}. It gave companies a clear progression rather than just telling them to “adopt AI.”
Where I’m still skeptical is on the vendor lock-in trajectory. Every powerful new feature is another proprietary function that doesn’t exist anywhere else. The more you build on AI_CLASSIFY and Cortex-generated Semantic Views, the harder it gets to leave. For healthcare organizations that already struggle with data portability, that’s not a small concern.
But I’ll say this: if you’re a data-focused company evaluating where to build, the Snowflake pitch right now is the most coherent version of “we’ll handle everything” that I’ve seen from a data platform. Whether that’s the right trade-off depends on how much you value optionality versus integration depth.
If you’re working through your own “make your data AI ready” journey, especially in healthcare, I’d love to hear what’s working for you. Connect with me on LinkedIn.

{kind=link}